

The Ultimate Face-Off: ServiceNow Apriel 15B’s Single-GPU Revolution vs. Google Gemini 2.5 Flash’s Cloud Power
The AI Wall of 2024
Let’s get real for a sec — enterprise AI hit a massive wall in 2024.
Seventy-three percent of companies said the same thing: “We just can’t afford the infrastructure.”
That was the breaking point. AI wasn’t the problem. The cost was.
Then came 2025.
A new wave of models changed the game — frontier-level intelligence that could run on a single GPU.
That’s not just an upgrade; that’s freedom.
And now we’re here — the biggest showdown in AI right now: ServiceNow Apriel 15B vs Google Gemini 2.5 Flash
One’s open, one’s closed. One fits in your desktop, the other floats in the cloud.
Both want the same crown — the future of cost-effective, real-time AI.
So if you’ve ever wondered whether a single GPU can actually compete with Google’s cloud giants, this post is your map.
TL;DR Summary Box
| 🧠 Category | Winner | Why |
|---|---|---|
| 💸 Cost & Access | Apriel 15B | Free weights, runs on one GPU |
| ⚙️ Scale & Context | Gemini 2.5 Flash | 1M-token context window |
| 🔐 Privacy & Control | Apriel 15B | MIT license, total local control |
1. Model Pedigree & Strategic Positioning

1.1 Creator Philosophies
Let’s start with their souls.
ServiceNow AI Research built Apriel 15B not to win a leaderboard but to break a ceiling.
Their goal: make frontier AI feel like open-source Linux did back in the early 2000s — powerful, flexible, free.
MIT license. Open weights. No gatekeeping.
Google AI, on the other hand, moves with precision and scale.
Gemini 2.5 Flash isn’t about accessibility; it’s about dominance.
It’s tied into the Vertex AI ecosystem, built for enterprises that already live in Google’s cloud.
Powerful, but gated. Scalable, but pricey.
So right from the start, this isn’t just a model fight.
It’s two ideologies colliding — open innovation vs. controlled perfection.
1.2 The Design Trade-Off
Apriel doesn’t try to compete in raw size.
It’s 15 billion parameters, compared to Gemini Flash’s ~120 billion.
But the magic lies in its “Thinker” design — a layered reasoning system that allows smaller models to think deeper without bloating memory.
It’s not about more neurons — it’s about smarter ones.
Gemini Flash, meanwhile, throws scale at every problem.
When you’ve got Google Cloud behind you, scale is easy.
But smaller players can’t play that game without burning a hole in their wallet.
1.3 Release Context
Timing tells stories.
Gemini 2.5 Flash dropped in June 2025, setting new standards for long-context processing.
It was fast, vast, and undeniably powerful.
But then came September 2025 — and Apriel 15B entered the scene.
ServiceNow’s message was loud and clear:
“You don’t need 10 GPUs or $10,000/month to run frontier AI.”
And suddenly, the single-GPU revolution began.
2. Deep Dive: Architecture and Technical Specs
2.1 Parameter Count & Efficiency
Here’s where the paradox begins.
How does a 15B model stand toe-to-toe with a 120B giant?
Apriel uses an advanced “Thinker” core that optimizes attention flow — fewer parameters but smarter routing.
Add aggressive pruning, modular reasoning layers, and efficient cross-modal fusion, and you’ve got near-frontier reasoning with a fraction of the cost.
Gemini Flash still wins in raw throughput, but Apriel’s lean design punches way above its weight.
2.2 Quantization & Memory
Here’s the big flex: Apriel 15B runs on 4-bit quantization.
That means it can comfortably live inside a single RTX 4090 or even an M2 Ultra Mac.
Memory footprint? Insanely small.
Speed? Surprisingly fast.
Gemini Flash, though, lives in another universe — proprietary optimization, 8-bit or 16-bit inference, and cloud TPUs only.
You can’t host it yourself.
You rent it.
So if you’re into tinkering, Apriel is your playground.
If you’re into scaling massive workloads, Gemini’s your suit-and-tie cloud beast.
2.3 Context Window Face-Off
Here’s the biggest brag Gemini has: 1,000,000 tokens.
It’s mind-blowing.
You can feed it an entire legal archive or a whole year’s worth of Slack chats.
Apriel? Still a beast at 128,000 tokens.
For 90% of enterprises, that’s more than enough — long reports, PDFs, knowledge bases, internal docs.
The question isn’t “how long?” — it’s “when does the extra context matter?”
For most users, it doesn’t.
But for lawyers, analysts, and compliance teams? That million-token stretch is gold.
2.4 Multimodal Capabilities
Both can see, read, and reason.
Apriel’s image reasoning is surprisingly sharp for its size, handling document vision, graphs, and screenshots easily.
Gemini Flash still wins in general multimodal accuracy — especially in multi-image reasoning and structured vision tasks.
But for cost-to-performance? Apriel’s a monster in its own lane.
3. The Deployment Revolution: Single-GPU Suitability
3.1 Apriel’s Local Edge
This is where things get wild.
Apriel 15B runs locally — no internet, no cloud, no vendor lock-in.
If you’ve got an RTX 4090 or an M-series Mac, you can deploy it in minutes.
No subscription. No meter running.
It’s built for small labs, indie developers, and startups tired of cloud bills.
(Visual Element 2: Deployment Diagram — Apriel Local GPU vs Gemini Cloud Stack)
3.2 Gemini’s Cloud Dependency
Gemini Flash lives in Google’s fortress — Vertex AI.
You can’t download it. You can only access it via API.
It’s brilliant for scaling global applications — customer service bots, multi-user data analysis, enterprise chat layers — but every token costs.
And that’s the trade-off: convenience for control.
3.3 Real-Time Latency Test
When you run Apriel locally, responses come from your GPU — instantly.
No network delay. No server queue.
Gemini’s fast too, but it’s limited by the cloud round-trip.
For short responses (<500 words), the latency difference is small.
For real-time applications, Apriel feels snappier — almost human-fast.
3.4 Hardware Requirements
Apriel 15B’s magic number: 24GB VRAM.
That’s all you need.
Gemini Flash? You’ll need multi-TPU or a Google Cloud setup that costs thousands per month.
So yeah, Apriel wins the accessibility game — hands down.
4. Head-to-Head Benchmark Performance
4.1 Core Reasoning Battle
Benchmarks don’t lie — they tell the truth in numbers.
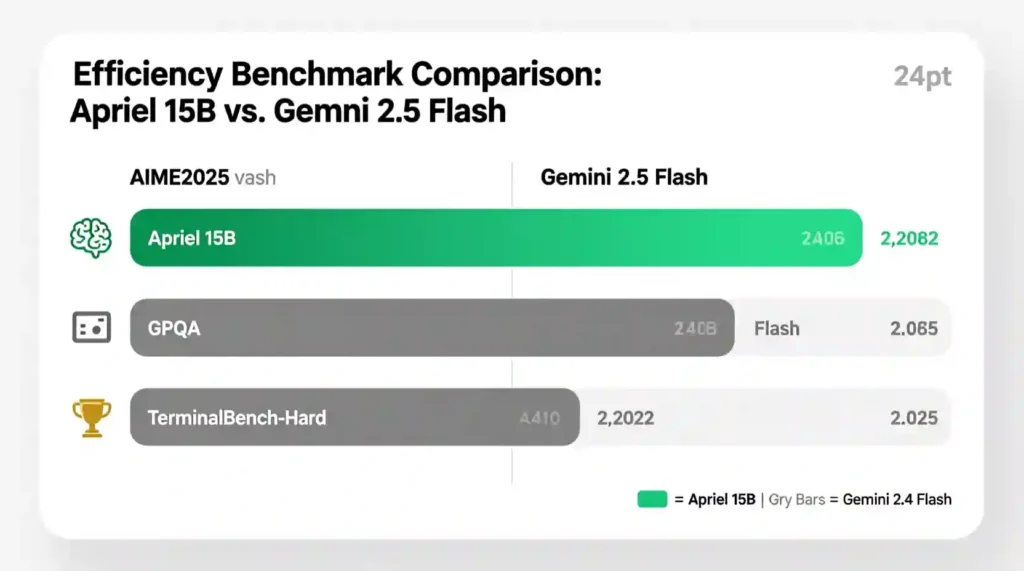
AIME2025: Apriel hits ~88, Gemini sits close at ~89.
That’s nearly identical reasoning — with one-eighth the size.
Think about that.
GPQA (Graduate Problem Questions): Apriel scores ~71, Gemini similar.
So when it comes to deep logic and step reasoning, both models are neck-and-neck.
4.2 Specialized Domain Metrics
On TerminalBench-Hard (system admin and coding), Gemini leads slightly at 13% vs 10%.
But the gap is small.
Apriel’s coding reasoning is already catching up through fine-tuning modules.
For LiveCodeBench and Tau²Bench-Telecom, Apriel impresses — consistent, reliable, and stable across use cases.
4.3 Performance-per-Parameter Ratio
Now, this is Apriel’s superpower.
Per parameter, it’s 6–8× more efficient than Gemini Flash.
That means better return for every watt of GPU you own.
Efficiency beats size. Every time.
4.4 Benchmark Summary ON Apriel 15B vs Google Gemini 2.5 Flash

| Benchmark | Apriel 15B | Gemini 2.5 Flash | Verdict |
|---|---|---|---|
| AIME2025 | 88 | 89 | Tie |
| GPQA | 71 | 72 | Tie |
| TerminalBench-Hard | 10 | 13 | Gemini slightly stronger |
| Efficiency (Score/Params) | 5.8x | 1x | Apriel wins |
5. Financial Deep Dive: Cost, TCO, and Monetization
5.1 Token Cost Showdown
Let’s talk dollars because that’s where the fight gets real.
- Apriel 15B: Effectively $0 per token if you run locally.
- Only costs are your GPU and electricity.
- Open weights = no API fees.
- Gemini 2.5 Flash: $0.30 per input and $2.50 per output per million tokens.
- Enterprise-grade cloud, premium pricing.
- Hidden fees can sneak up — cloud egress, extra storage, and API overages.
If your AI work is heavy, local Apriel suddenly looks like a golden goose.
5.2 Total Cost of Ownership (TCO) Analysis
Scenario: 1 million tokens per month for a year
- Apriel: One-time GPU purchase (say, RTX 4090 at $1,500), electricity ~ $200/year.
- TCO: ~$1,700.
- Gemini: 1M tokens/month = $36k/year, plus cloud overhead and potential scaling costs.
The gap isn’t small — it’s staggering.
Hidden Costs:
- Apriel: occasional driver updates, minor maintenance, software fine-tuning.
- Gemini Flash: API pricing spikes, latency scaling, and vendor lock-in.
5.3 Break-Even Analysis
Here’s the kicker:
If your usage hits ~100k tokens per month, Apriel already starts to outperform Gemini cost-wise.
Hit 1M tokens, and you’re saving tens of thousands.
Apriel doesn’t just save money. It frees you from dependency.
5.4 ROI Scenarios
- Apriel: High ROI for private research, massive datasets, and cost-sensitive startups.
- Gemini Flash: High ROI for ultra-long context projects, like legal analytics or real-time customer interactions.
Pick your battleground — one model shines where cost is king, the other where context rules.
6. Ecosystem, Community, and The Open-Source Factor
6.1 The Open vs. Closed Divide
Apriel is MIT licensed, meaning full access, modifiable code, and no strings attached.
Gemini Flash is proprietary, API-only — you rent intelligence, you don’t own it.
Open vs closed isn’t just philosophical. It’s financial, operational, and ethical.
6.2 Developer Accessibility
- Apriel: Hugging Face integration, community fine-tuning, plugin ecosystem.
- Gemini Flash: Google-backed documentation, seamless Vertex AI integration, enterprise support.
For solo devs and small teams, Apriel’s freedom beats Gemini’s polished-but-locked ecosystem.
6.3 Controversy & Limitations
- Apriel: Setup complexity for beginners, occasional edge-device slowdown.
- Gemini Flash: Potential censorship or AI guardrails, high operational cost.
Every model has a price — literal and figurative.
6.4 Expert Opinion and Community Sentiment
- Reddit chatter: “Apriel is the first AI I feel I can actually own.”
- HN thread: “Gemini is fast, but cost is brutal for small labs.”
- Researchers: “Apriel proves that efficiency matters more than sheer size.”
Social proof aligns with what the numbers already hint — two distinct worlds colliding.
7. Ideal Use Cases and When NOT to Use Each Model
7.1 Use Cases Breakdown
Apriel Wins:
- Confidential document analysis
- Developer coding assistance
- Research tasks requiring long-running local computation
- Cost-sensitive startups
Gemini Flash Wins:
- Ultra-long legal/financial context
- Real-time customer-facing applications
- Rapid API prototyping at scale
7.2 “Anti-Use Cases”
- Avoid Apriel if you need instant, out-of-the-box AI with zero technical setup.
- Avoid Gemini Flash if privacy or predictable costs are non-negotiable.
7.3 Real-World Mini Case Studies
- Apriel Example: University lab analyzing genomic datasets privately without cloud costs.
- Gemini Flash Example: E-commerce company handling thousands of real-time support chats with Vertex AI.
These examples highlight the practical trade-offs — cost, speed, context, and control.
8. Future Roadmap & Impact on AI Democratization
8.1 Planned Updates
- Apriel: Expanding context window, better multimodal reasoning.
- Gemini: Introducing agentic features and more enterprise APIs.
8.2 Competitive Landscape Threats
Other models like DeepSeek could shake the duopoly.
But right now, Apriel vs Gemini is the duel to watch.
8.3 The Democratization Factor
Apriel challenges cloud monopoly.
Open weights, local deployment, and minimal hardware needs make frontier AI accessible — not just for tech giants, but for real humans doing real work.
👑 Conclusion and Definitive Verdicts
We’ve walked through everything — specs, benchmarks, deployment, cost, and real-world use.
Here’s the raw truth: the single-GPU frontier is here, and it’s not waiting for enterprise budgets to catch up.
ServiceNow Apriel 15B vs Google Gemini 2.5 Flash isn’t just a model comparison. It’s a battle of philosophies:
- Apriel 15B: Local control, open-source freedom, cost-efficient, highly efficient per parameter.
- Gemini 2.5 Flash: Ultra-scale, massive context, cloud-optimized, enterprise-ready.
Now let’s slice it down into actionable decisions.
Quick Decision Flowchart (Visual Element 4)
| Question | YES → | NO → |
|---|---|---|
| Is TCO your #1 concern? | Choose Apriel 15B | Next question |
| Do you need >200K token context? | Choose Gemini Flash | Choose Apriel 15B |
| Are you deploying on local GPU hardware? | Apriel 15B | Gemini Flash |
| Need real-time, enterprise-scale cloud services? | Gemini Flash | Apriel 15B |
Winner Breakdown
Best for Startups / Privacy: ServiceNow Apriel 15B
- Local deployment
- Predictable costs
- Data stays in-house
Best for Ultra-Scale / Context: Google Gemini 2.5 Flash
- 1M-token context window
- Real-time cloud scalability
- Enterprise-level integration
Best Price-to-Performance: ServiceNow Apriel 15B
- Tiny TCO
- High efficiency per parameter
- Open-source flexibility
📊 In-Depth Side-by-Side Comparison Table
| Feature | ServiceNow Apriel 15B Thinker | Google Gemini 2.5 Flash | Impact Analysis |
|---|---|---|---|
| Creator | ServiceNow AI Research | Google AI | Apriel focuses on democratization; Gemini focuses on cloud scale |
| Model Type | Multimodal, OpenWeights | Multimodal, Proprietary | Transparency vs enterprise-managed access |
| Deployment Suitability | Single GPU (>16GB VRAM), Edge Devices | Multi-GPU, Cloud TPU, Vertex AI | Apriel = accessible & cheap, Gemini = scalable & expensive |
| Quantization Support | Aggressive 4-bit | Limited public info | Apriel = optimized for local speed |
| Context Window Size | 128,000 tokens | 1,000,000 tokens | Gemini dominates long-context applications |
| Core Reasoning (AIME2025) | ~88% | ~89% | Nearly identical reasoning, Apriel smaller footprint |
| TerminalBench-Hard (Coding) | 10% | 13% | Gemini slightly better at technical tasks |
| Cost per 1M Tokens | ~$0 (local) | $0.30 input / $2.50 output | Apriel dramatically cheaper |
| Licensing | MIT License (Open weights) | Proprietary | Ownership vs rent |
| TCO | Low, predictable | High, usage-based | Apriel wins for budget-conscious teams |
Final Thoughts ON Apriel 15B vs Google Gemini 2.5 Flash
Here’s the soul of it: you don’t have to choose between high performance and affordability anymore.
- If you want freedom, low-cost, privacy, and single-GPU deployment, Apriel 15B is your champion.
- If you want ultra-scale reasoning, massive context, and seamless cloud integration, Gemini Flash is your powerhouse.
The 2025 AI frontier isn’t just about who has the biggest model.
It’s about who empowers the most people, who makes AI accessible, and who lets humans — not just cloud giants — decide how intelligence is used.
So yes, the single-GPU revolution is real. And for most of us, Apriel 15B isn’t just enough — it’s perfect.
Pingback: Grok 3 vs Claude 3.7: AI Coding Battle 2025 - zadaaitools.com