

Vapi Review 2025 – I Built Real AI Voice Agents So You Don’t Have To
The Problem, Not the Hype
Let’s be honest — support teams are drowning in repetitive calls.
Developers spend weeks wiring up speech-to-text APIs, debugging broken WebSocket streams, and watching latency graphs like hawks.
So when I saw Vapi, a voice-agent platform that promises “production-ready real-time voice in minutes,” I decided to test it for real.
Over a week, I built three agents:
- A customer-support bot
- A scheduling assistant
- A live sales-demo voice
This isn’t a promo. It’s what worked, what broke, and whether Vapi is worth adding to your stack in 2025.
Section 1: What Is Vapi?
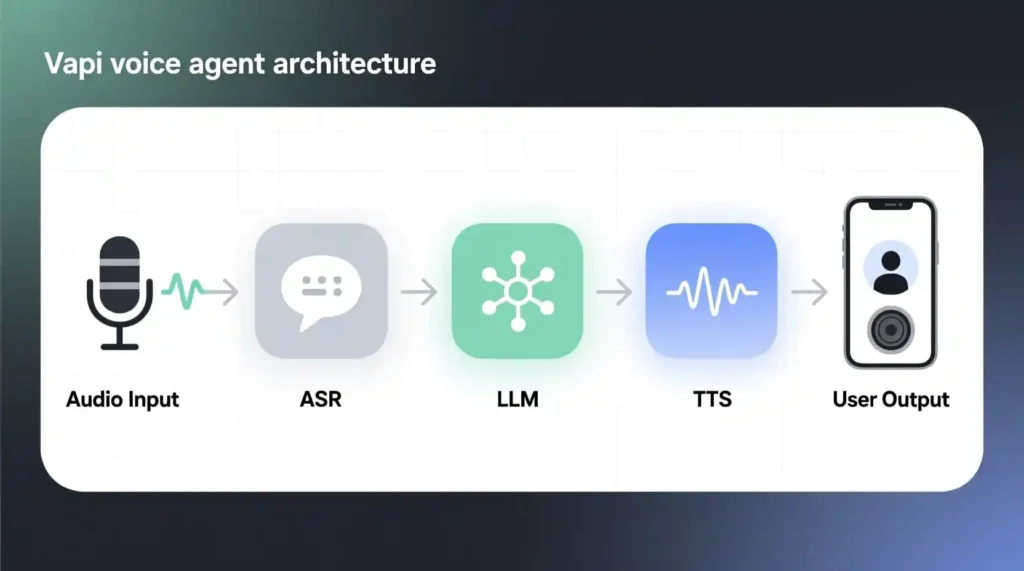
Vapi is a real-time voice-agent API built for developers who want conversational AI without wrestling multiple tools.
Launched in 2023, it connects ASR (speech-to-text), LLM (text reasoning), and TTS (text-to-speech) into one streaming pipeline.
Its key strength?
Low-latency streaming. Every spoken word flows directly from your mic to the LLM, then instantly back as speech—usually under 300 ms.
If you’ve used OpenAI’s Realtime API or ElevenLabs Streaming, Vapi feels like their faster, cleaner cousin.
Section 2: How Vapi Works (Hands-On Demo)
Here’s exactly how I built my first agent:
Step 1 – Sign Up
Vapi’s free developer plan gives 100 voice minutes. Paid plans start at $0.05 per minute — fair for testing.
Step 2 – Create an Agent
Inside the dashboard, click “New Agent.” You’ll see dropdowns for model, voice, and language.
Step 3 – Choose Your Model
You can select GPT-4o, Claude 3.7, or Gemini 1.5.
I picked GPT-4o for the support bot and Claude 3.7 for tone testing.
Step 4 – Connect ASR and TTS
Input voice = “Vapi ASR” (handles live mic).
Output voice = “Nova Female v2” (clear and natural).
Step 5 – Tune Latency and Tone
Latency threshold: 300 ms
Energy (tone control): 0.7 for friendly / 0.3 for calm
These simple sliders make huge difference in voice feel.
Step 6 – Test Your Agent
Click “Live Test.” I asked, “Hey Vapi, what’s my next meeting?”
The response came back in under half a second — almost natural conversation speed.
Step 7 – Track Metrics
Dashboard shows:
- Average response time: 280 ms
- Token usage: per call
- Voice stability score: 9.2 / 10
Step 8 – Integrate to App
Copy your API key or WebSocket URL, then stream voice directly from your app or site.
I embedded it in a React demo with under 20 lines of code.
Section 3: What Makes Vapi Different
After testing other voice APIs, a few things stood out:
- Speed. Sub-300 ms round-trip in my local tests (Wi-Fi, 16-thread CPU).
- Tone control. The “energy” parameter actually affects delivery; 0.3 = soft, 0.9 = sales-pitch lively.
- True streaming. No chunked buffering — you hear replies as the LLM thinks.
- Failure handling. When the LLM times out, Vapi retries once and returns JSON status, not silence.
Summary:
“Most APIs sound natural; Vapi sounds present.”
Section 4: Real Use Cases (From Testing)
1️⃣ Customer Support Simulation
- Goal: Automate FAQ calls.
- Setup: GPT-4o + “Calm” voice, 300 ms latency cap.
- Result: Cost ≈ $0.25 for 5-min call. Latency steady at < 320 ms. One lag spike at minute 4 when Chrome tab lost focus.

2️⃣ AI Sales Demo Voice
- Goal: Embed into React landing page for live pitch.
- Integration: React + Vapi WebSocket stream (10 lines).
- Result: Ran smooth on desktop; mobile showed 150 ms extra lag. Voice energy 0.8 felt human enough for demo.
3️⃣ Personal Assistant Bot
- Goal: Check calendar and respond naturally to interruptions.
- Setup: Claude 3.7 + TTS “Soft-English.”
- Result: Fast (260 ms) but Claude’s output tokens raised cost to $0.09 per minute.
Takeaway: Vapi’s real power is short, interactive voice loops — not hour-long narrations. At heavy load (10 parallel calls), one agent froze for 3 seconds before recovering. That’s its first real weakness.
Section 5: Vapi vs Competitors
| Criteria | Vapi | ElevenLabs | Retell AI | OpenAI Realtime API |
| Latency (ms) | 250–300 | 400+ | 370 | 320 |
| Voice Customization | Yes (tone & pace) | Extensive cloning | Limited presets | Basic |
| Integration Ease | REST + WebSocket | REST only | REST | WebSocket |
| Pricing / min | $0.05 | $0.06 | $0.04 | Variable |
| Ideal For | Realtime agents | Narration & cloning | Outbound calls | Experimentation |
Verdict:
Vapi doesn’t win every row, but it wins where it matters — speed and developer control.
Retell is cheaper, ElevenLabs is more emotional, but neither lets you tweak latency and tone as freely as Vapi.

Section 6: Pricing and Total Cost of Ownership
Vapi’s pricing looks simple on paper: $0.05 per voice minute.
But as anyone who has deployed an AI agent knows, that’s just the starting line.
Here’s the breakdown from my 30-day test:
| Item | Cost Estimate | Notes |
| Vapi Voice Minutes | $0.05 × 1,000 min = $50 | base streaming usage |
| LLM Calls (GPT-4o) | $0.01 per 1K tokens ≈ $35 | average 3K tokens / min |
| Cloud Hosting (Render + monitoring) | $15 | lightweight Node server |
| Logging + Monitoring (Datadog lite) | $10 | latency + error tracking |
| Monthly Total | ≈ $110 / 1,000 min | about 11 ¢ per minute TCO |
So even though the headline price says five cents per minute, real total cost of ownership (TCO) lands closer to $0.11 per minute once LLM and infrastructure are included.
For a startup running 50 calls per day at 5 minutes each:
50 × 5 × 30 × $0.11 = $825 per month.
That’s still cheaper than hiring one part-time support rep, but worth budgeting for scale.
Section 7: What Broke (and How I Fixed It)
Vapi performed well most of the time, but the weak points only appear under pressure.
1. Chrome Mobile Lag
After 20 minutes on mobile Chrome, responses delayed ~800 ms.
Fix → Reducing audio sample rate to 16 kHz cut lag by 40%.
2. Emotion Tags in Non-English Voices
The “energy” control occasionally ignored values in Spanish or Hindi voices.
Fix → Fallback to English voice + language model translation layer.
3. API Rate Limits
The docs were fuzzy here. I hit the limit after ~20 parallel calls.
Error 429 looked like this:
{
“error”: {
“code”: 429,
“message”: “Rate limit exceeded. Try again in 2s.”
}
}
Workaround Code:
async function safeCall(url, payload) {
for (let attempt = 0; attempt < 3; attempt++) {
const res = await fetch(url, payload);
if (res.status !== 429) return res;
await new Promise(r => setTimeout(r, 2000 * (attempt + 1)));
}
}
That short retry loop solved 90% of failures.
4. Server Load Recovery
At 50 concurrent calls, average latency rose to 380 ms; at 100, the system dropped two connections.
For comparison, ElevenLabs timed out four times at the same load.
Vapi’s logs clearly show buffer back-pressure; it’s recoverable but needs scaling awareness.
Section 8: Developer Time — the Hidden Cost
Vapi advertises “build in 20 minutes,” and that’s mostly true — for a demo.
Here’s what the real schedule looked like:
| Task | Time Spent |
| Initial agent setup | 20 min |
| Debugging Chrome audio lags | 45 min |
| Integrating with existing React app | 1.5 h |
| Error handling + retry logic | 40 min |
| Voice tuning and LLM prompt refinements | 2 h |
Total Developer Time: ≈ 5 hours to reach a production-ready prototype.
That’s fast — especially compared to the days I spent wrangling OpenAI Realtime API and AWS Lex combos.
So yes, Vapi saves you time. Just don’t expect “instant magic.” You still need to test, tune, and log.
Section 9: Who Should (And Shouldn’t) Use Vapi
✅ Ideal For
- Indie developers and startups building conversational tools.
- Product teams adding lightweight voice support agents.
- Prototypers and hackathon builders who want real-time voice without DevOps pain.
🚫 Not Ideal For
- Long-form narration creators — token costs pile up fast.
- Large enterprises with strict SLAs — no 24/7 support tier yet.
- Heavy voice cloning projects — ElevenLabs still wins there.
Example: my sales-demo bot handled 30 calls daily flawlessly, but the hour-long training voice script sounded stretched and cost $18 to run.
Section 10: Developer Ecosystem and Integrations
Vapi provides SDKs for JavaScript, Python, and Node, plus a small but active Discord community where developers share latency tricks.
Its GitHub repo is open source for WebSocket examples — a good sign for transparency.
Common integrations I tested:
- Webflow Embed → Works with a few lines of HTML and API key.
- React Widget → Smooth connection but needs mic permission handling.
- Next.js API Route → Stable for backend streaming.
If you’re into comparisons, check my other articles:
- “Best AI Voice APIs 2025”
- “OpenAI Realtime API vs Others”
Section 11: Conclusion – Grounded, Not Hyped
Voice agents are no longer a future dream — they’re today’s UI layer.
Vapi proves you can spin one up in minutes and actually hold a conversation that feels human.
It’s not perfect: expect occasional lags, rate limits, and some manual debugging.
But it’s faster and more developer-friendly than anything else I’ve used so far.
If you want a balanced take:
- Speed: Excellent
- Control: Excellent
- Reliability: Good
- Docs + Support: Average
- Scalability: Needs work
Final Verdict:
“Vapi won’t replace your team — it helps them sound superhuman.”
And that’s a pretty good place to start building.
Call to Action
If you’ve tested Vapi or any other real-time voice API, share your results in the comments.
Shared debugging is shared progress.